 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMVIAD: Multi-view Multi-task Video Understanding for Industrial Anomaly Detection
May 11, 2026Industrial anomaly detection is critical for manufacturing quality control, yet existing datasets mainly focus on static images or sparse views, which do not fully reflect continuous inspection processes in real industrial scenarios. We introduce MMVIAD (Multi-view Multi-task Video Industrial Anomaly Detection), to the best of our knowledge the first continuous multi-view video dataset for industrial anomaly detection and understanding, together with a benchmark for multi-task evaluation. MMVIAD contains object-centric 2-second inspection clips with approximately 120 degrees of camera motion, covering 48 object categories, 14 environments, and 6 structural anomaly types. It supports anomaly detection, defect classification, object classification, and anomaly visible-time localization. Systematic evaluations on MMVIAD show that current commercial and open-source video MLLMs remain far below human performance, especially for fine-grained defect recognition and temporal grounding. To improve transferable anomaly understanding, we further develop a two-stage post-training pipeline where PS-SFT (Perception-Structured Supervised Fine-Tuning) initializes perception-structured reasoning and VISTA-GRPO (Visibility-grounded Industrial Structured Temporal Anomaly Group Relative Policy Optimization) refines the model with semantic-gated defect reward and visibility-aware temporal reward, producing the final model VISTA. On MMVIAD-Unseen, VISTA improves the base model's average score across the four tasks from 45.0 to 57.5, surpassing GPT-5.4. Source code is available at https://github.com/Georgekeepmoving/MMVIAD.
Beyond the Last Layer: Multi-Layer Representation Fusion for Visual Tokenizatio
May 11, 2026Representation autoencoders that reuse frozen pretrained vision encoders as visual tokenizers have achieved strong reconstruction and generation quality. However, existing methods universally extract features from only the last encoder layer, discarding the rich hierarchical information distributed across intermediate layers. We show that low-level visual details survive in the last layer merely as attenuated residuals after multiple layers of semantic abstraction, and that explicitly fusing multi-layer features can substantially recover this lost information. We propose DRoRAE (Depth-Routed Representation AutoEncoder), a lightweight fusion module that adaptively aggregates all encoder layers via energy-constrained routing and incremental correction, producing an enriched latent compatible with a frozen pretrained decoder. A three-phase decoupled training strategy first learns the fusion under the implicit distributional constraint of the frozen decoder, then fine-tunes the decoder to fully exploit the enriched representation. On ImageNet-256, DRoRAE reduces rFID from 0.57 to 0.29 and improves generation FID from 1.74 to 1.65 (with AutoGuidance), with gains also transferring to text-to-image synthesis. Furthermore, we uncover a log-linear scaling law ($R^2{=}0.86$) between fusion capacity and reconstruction quality, identifying \textit{representation richness} as a new, predictably scalable dimension for visual tokenizers analogous to vocabulary size in NLP.
Unveiling Fine-Grained Visual Traces: Evaluating Multimodal Interleaved Reasoning Chains in Multimodal STEM Tasks
Apr 21, 2026Multimodal large language models (MLLMs) have shown promising reasoning abilities, yet evaluating their performance in specialized domains remains challenging. STEM reasoning is a particularly valuable testbed because it provides highly verifiable feedback, but existing benchmarks often permit unimodal shortcuts due to modality redundancy and focus mainly on final-answer accuracy, overlooking the reasoning process itself. To address this challenge, we introduce StepSTEM: a graduate-level benchmark of 283 problems across mathematics, physics, chemistry, biology, and engineering for fine-grained evaluation of cross-modal reasoning in MLLMs. StepSTEM is constructed through a rigorous curation pipeline that enforces strict complementarity between textual and visual inputs. We further propose a general step-level evaluation framework for both text-only chain-of-thought and interleaved image-text reasoning, using dynamic programming to align predicted reasoning steps with multiple reference solutions. Experiments across a wide range of models show that current MLLMs still rely heavily on textual reasoning, with even Gemini 3.1 Pro and Claude Opus 4.6 achieving only 38.29% accuracy. These results highlight substantial headroom for genuine cross-modal STEM reasoning and position StepSTEM as a benchmark for fine-grained evaluation of multimodal reasoning. Source code is available at https://github.com/lll-hhh/STEPSTEM.
Heterogeneous Mixture-of-Experts for Energy-Efficient Multimodal ISAC in Highly Mobile Networks
Apr 08, 2026The integration of multimodal sensing and millimeter-wave (mmWave) communications is a key enabler for highly mobile vehicle-to-infrastructure (V2I) networks. However, continuous high-resolution visual sensing incurs prohibitive computational energy, while delayed sensing information worsens beam misalignment. In this paper, we establish a physics-aware multimodel integrated sensing and communication (M-ISAC) framework that quantifies the mathematical trade-off between sensing energy and communication reliability using the semantic age of information (AoI). To address the coupled challenges of temporal AoI evolution and instantaneous non-convex constant modulus constraints, we propose a novel reinforcement learning approach empowered by a heterogeneous mixture-of-experts (RL-H-MoE) architecture. By strictly decoupling the temporal scheduling and spatial phase mapping, the RL-H-MoE avoids prevalent gradient conflicts in multi-task learning. Extensive simulations demonstrate that the proposed architecture achieves an optimal event-triggered sensing policy, significantly minimizing the long-term system cost while guaranteeing ultra-low sensing errors and reliable physical-layer link connectivity.
LongCat-Next: Lexicalizing Modalities as Discrete Tokens
Mar 29, 2026The prevailing Next-Token Prediction (NTP) paradigm has driven the success of large language models through discrete autoregressive modeling. However, contemporary multimodal systems remain language-centric, often treating non-linguistic modalities as external attachments, leading to fragmented architectures and suboptimal integration. To transcend this limitation, we introduce Discrete Native Autoregressive (DiNA), a unified framework that represents multimodal information within a shared discrete space, enabling a consistent and principled autoregressive modeling across modalities. A key innovation is the Discrete Native Any-resolution Visual Transformer (dNaViT), which performs tokenization and de-tokenization at arbitrary resolutions, transforming continuous visual signals into hierarchical discrete tokens. Building on this foundation, we develop LongCat-Next, a native multimodal model that processes text, vision, and audio under a single autoregressive objective with minimal modality-specific design. As an industrial-strength foundation model, it excels at seeing, painting, and talking within a single framework, achieving strong performance across a wide range of multimodal benchmarks. In particular, LongCat-Next addresses the long-standing performance ceiling of discrete vision modeling on understanding tasks and provides a unified approach to effectively reconcile the conflict between understanding and generation. As an attempt toward native multimodality, we open-source the LongCat-Next and its tokenizers, hoping to foster further research and development in the community. GitHub: https://github.com/meituan-longcat/LongCat-Next
Extended-Target Classification and Localization for Near-Field ISAC
Mar 24, 2026Near-field integrated sensing and communication (ISAC) enables object-level sensing from distance-dependent array responses, yet most existing near-field methods still rely on point-target models and realistic extended targets remain largely unexplored. In this paper, joint target classification and range-azimuth localization are studied from channel responses of realistic extended targets. A dual-branch inference framework is proposed. Semantic and geometric branches are used for classification and localization, respectively. Cross-task attention is introduced after task-specific encoding so that complementary cues can be exchanged without forcing full feature sharing from the input stage. To improve localization on the same backbone, uncertainty-aware regression and a physics-guided structured objective are adopted, including planar consistency, peak-response regularization, and geometry-coupling constraints. Training and evaluation data are generated from full-wave electromagnetic scattering simulations of voxelized vehicle targets with randomized heading angles, material contrasts, and placements. The compared variants show that cross-task attention mainly benefits classification, while uncertainty-aware and structured supervision are needed to recover strong localization performance on the same backbone. Under the adopted shared-OFDM benchmark, the proposed framework reaches the best joint operating point with fewer sensing tones for the same target performance region.
A Spatio-Temporal-Frequency Transformer Framework for Near-Field Target Recognition
Mar 16, 2026A target recognition framework relying on near-field integrated sensing and communication (ISAC) systems is proposed. By exploiting the distance-dependent spatial signatures provided by the near-field spherical wavefront, high-accuracy sensing is realized in a bandwidth-efficient manner. A spatio--temporal--frequency (STF) transformer framework is introduced for target recognition using electromagnetic features found in the wireless channel response. In particular, a lightweight spatial encoder is employed to extract features from the antenna array for each frame and subcarrier. These features are then fused by a time-frequency transformer head with positional embeddings to model temporal dynamics and cross-subcarrier correlations. Simulation results demonstrate that strong target recognition performance can be achieved even with limited bandwidth resources.
Score-Based Conditional Flow Models for MIMO Receiver Design with Superimposed Pilots
Feb 25, 2026Accurate channel state information (CSI) is vital for multiple-input multiple-output (MIMO) systems. However, superimposed pilots (SIP), which reduce overhead, introduce severe pilot contamination and data interference, complicating joint channel estimation and data detection. This paper proposes a conditional flow matching receiver (CFM-Rx), an unsupervised generative framework that learns directly from received signals, eliminating the need for labeled data and improving adaptability across diverse system settings. By leveraging flow-based generative modeling, CFM-Rx enables deterministic, low-latency inference and exploits model invertibility to capture the bidirectional nature of signal propagation. This framework unifies flow matching with score-based diffusion modeling via a moment-consistent ordinary differential equation (ODE), replacing stochastic differential equation (SDE) sampling with a deterministic and efficient process. Furthermore, it integrates receiver-side priors to ensure stable, data-consistent inference. Extensive simulation results across various MIMO configurations demonstrate that CFM-Rx consistently outperforms conventional estimators and state-of-the-art data-driven receivers, achieving notable gains in channel estimation accuracy and symbol detection robustness, particularly under severe pilot contamination.
Two Pathways to Truthfulness: On the Intrinsic Encoding of LLM Hallucinations
Jan 12, 2026Despite their impressive capabilities, large language models (LLMs) frequently generate hallucinations. Previous work shows that their internal states encode rich signals of truthfulness, yet the origins and mechanisms of these signals remain unclear. In this paper, we demonstrate that truthfulness cues arise from two distinct information pathways: (1) a Question-Anchored pathway that depends on question-answer information flow, and (2) an Answer-Anchored pathway that derives self-contained evidence from the generated answer itself. First, we validate and disentangle these pathways through attention knockout and token patching. Afterwards, we uncover notable and intriguing properties of these two mechanisms. Further experiments reveal that (1) the two mechanisms are closely associated with LLM knowledge boundaries; and (2) internal representations are aware of their distinctions. Finally, building on these insightful findings, two applications are proposed to enhance hallucination detection performance. Overall, our work provides new insight into how LLMs internally encode truthfulness, offering directions for more reliable and self-aware generative systems.
Dynamic Residual Encoding with Slide-Level Contrastive Learning for End-to-End Whole Slide Image Representation
Nov 07, 2025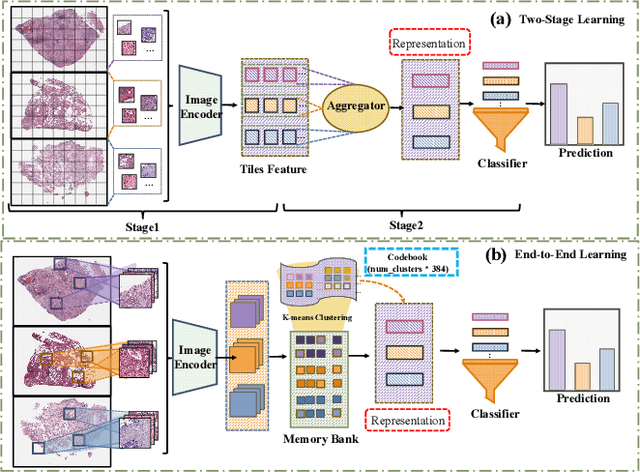

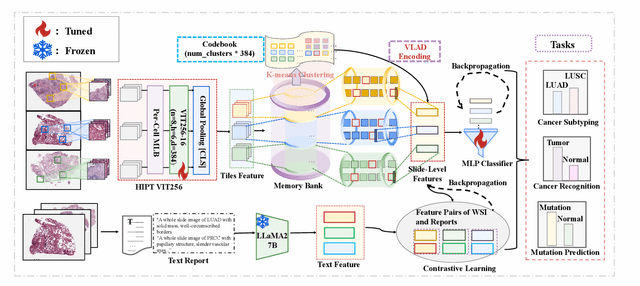
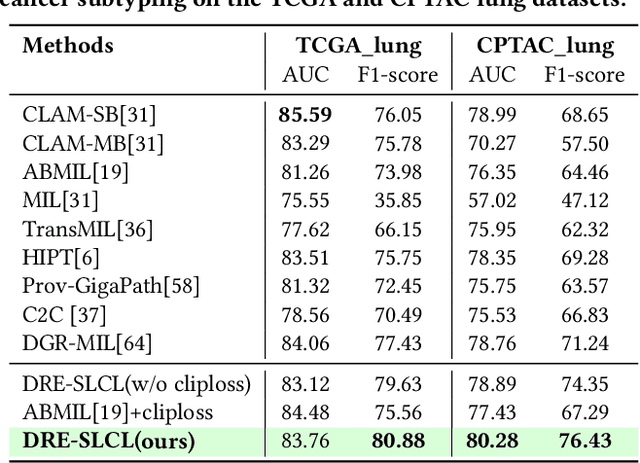
Whole Slide Image (WSI) representation is critical for cancer subtyping, cancer recognition and mutation prediction.Training an end-to-end WSI representation model poses significant challenges, as a standard gigapixel slide can contain tens of thousands of image tiles, making it difficult to compute gradients of all tiles in a single mini-batch due to current GPU limitations. To address this challenge, we propose a method of dynamic residual encoding with slide-level contrastive learning (DRE-SLCL) for end-to-end WSI representation. Our approach utilizes a memory bank to store the features of tiles across all WSIs in the dataset. During training, a mini-batch usually contains multiple WSIs. For each WSI in the batch, a subset of tiles is randomly sampled and their features are computed using a tile encoder. Then, additional tile features from the same WSI are selected from the memory bank. The representation of each individual WSI is generated using a residual encoding technique that incorporates both the sampled features and those retrieved from the memory bank. Finally, the slide-level contrastive loss is computed based on the representations and histopathology reports ofthe WSIs within the mini-batch. Experiments conducted over cancer subtyping, cancer recognition, and mutation prediction tasks proved the effectiveness of the proposed DRE-SLCL method.
* 8pages, 3figures, published to ACM Digital Library